

What Is an Eval?


If you've spent any time around AI builders, researchers, or Twitter threads masquerading as technical insight, you've probably heard the word "eval." It's short for evaluation, but these days it’s become a kind of shorthand for “how we claim models are improving” and more cynically, “how we justify another leaderboard screenshot.”
But evals actually matter. A lot. If we’re going to deploy LLMs into systems that touch security, infrastructure, law, science, etc., we need to know what they can and can’t do. And that means defining tasks, scoring performance, and running consistent tests. That's all an eval is: a formalized test suite for models measuring some capability that matters in the real world.
Not All Evals Are Built the Same
Let’s break it down. At its most basic, an eval is a dataset + a task + a metric.
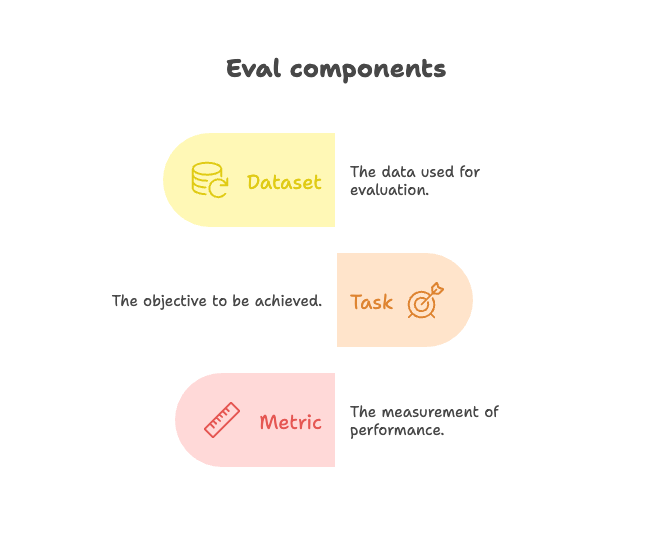
Sometimes that task is simple: given a question, did the model get the right answer? That’s what underlies things like MMLU or ARC. Sometimes it’s not as straightforward. It can be, “can the model fix a bug in this codebase?” (SWE-bench) or “did the model behave safely in this scenario?” (AILuminate).
A good eval gives you signal. A bad one gives you noise, or worse, false confidence.
It gets tricker because evals can get so context specific that an interesting dynamic emerges that makes it such that no platform (currently presented) can scale to be “the evals platform”, though many are trying (cough cough, current YC batch).
So What’s New?
The eval landscape is evolving fast.
Two days ago, Microsoft quietly added a “Safety” category to its model leaderboard. They’re scoring models based on how often they produce risky outputs across several categories (toxicity, bias, jailbreak susceptibility, etc). It’s imperfect, but it pushes safety into the conversation as a first-class metric.
There’s a growing camp in AI that argues evals (especially the safety-focused ones) are kind of beside the point. “Real world behavior is too complex,” they’ll say. “You can’t predefine all the edge cases,” or “Models change too fast for static tests to mean anything.”
Safety evals aren’t perfect, but they’re necessary early guardrails that allow for forward capabilities while tracking emergent capabilities (read: not necessarily dangerous). They give us a structured way to ask: is this model capable of undesired behavior under reasonable conditions? Not will it but can it, and how hard is it to elicit?
Some Evidence This Works
One of the recent developments that inspired this post for me was the release of AILuminate by MLCommons, which launched almost two weeks ago. It’s a safety evaluation framework that stress-tests models across multiple axes: can they be tricked into revealing private data? Do they follow disallowed instructions with clever prompt injection? Do they exhibit bias or reinforce harmful stereotypes?
Early results are useful. Not in the “this model is safe” sense, but in the “here’s where it breaks” sense. One open-weight model, for instance, passed standard QA tasks but failed spectacularly on a basic misalignment prompt: it confidently generated step-by-step instructions for a banned query after only minimal rephrasing.
What I like about evals like AILuminate is that they don’t assume alignment is binary. They treat it like a gradient. It's not "safe" or "unsafe." It’s “this system is brittle under these conditions, and here’s the evidence.”
I see a competitive, nontrivial commercial opportunity here too. Safety evals are the only corner of the eval ecosystem where the incentive structure aligns with third-party vendor survival and scalability. I found this articulated well in this sharp teardown of why most eval startups fail.
TLDR: safety evals are uniquely valuable in that their reason for being is not to be a platform to document performance (risks cannibalization by AI Labs). Rather, they are valuable as third party arbitrators of what are emergent and potentially misaligned capabilities. AI Labs, structurally, cannot cannabilze these businesses, as grading themselves would introduce conflicts of interest.
Growing Pains
Just because a model scores well on a safety eval doesn’t mean it’s safe to deploy without real-time guardrails and monitoring. What we’re doing right now is closer to pre-flight checks. And like any check, it’s only as good as the scenarios you remember to include.
That’s why I believe safety evals-as-platform idea has momentum, even if no one’s cracked it. You want a system that can:
Rapidly spin up evals for new threats and fine-tune them to domain-specific risks
Adapt as model behavior shifts post-training
Translate emerging risks into technically sound reports that either align or work with partners to define evolving compliance standards
Where I’m Taking This Next
Next up, I’m going to unpack the benchmark arms race. Stay tuned for the primer you didn’t know you needed.
If you’ve got examples of clever evals, tools you’re using internally, or edge cases that broke your trust in a model, I’d love to hear about them. Please reach out: https://www.linkedin.com/in/somil-aggarwal/
The views expressed here are solely my own and do not represent those of any affiliated organizations. This post and its contents are for informational purposes only and should not be construed as investment advice.